Understanding AI Inference: LLMs, Embeddings, and Reranking
By
Cloud Product Team • 7 min read •August 31, 2025
Introduction
Inference is the process that makes AI models useful in the real world. Whether generating text, analyzing patterns, or ranking results, inference is how trained models deliver value.
But not all inference is the same. Different workloads require different approaches. Understanding these types helps organizations choose the right tools for the job while staying compliant and secure.
Why Inference Matters
Training creates the intelligence, but inference is where that intelligence is applied. Without inference, even the most advanced model is just static potential.
Organizations use inference to:
- Generate natural language responses
- Power semantic search
- Classify documents or images
- Rank and rerank results for better accuracy
The type of inference determines both the quality of outcomes and the resources required.
LLM Inference
Large Language Model (LLM) inference focuses on generating human-like responses to text prompts. This is the backbone of many AI applications, from chatbots to knowledge assistants to automated document drafting.
LLM inference requires significant compute power and careful optimization. It also raises data sovereignty concerns when run on foreign cloud providers. SITE Cloud provides a sovereign alternative, ensuring LLM inference runs securely and locally.
Embedding Inference
Embeddings transform text, images, or other data into numerical vectors that capture meaning. These vectors are essential for tasks like semantic search, clustering, and recommendation engines.
They could be thought of as a map of meanings. For example, the words car and automobile may look different on the surface, but embeddings place them close together on the map because they mean the same thing. This is what makes features like “search by meaning” possible.
Embedding inference enables systems to find relevant information even if the exact words do not match. A user looking for “laptops for travel” could still be shown results that mention “lightweight notebooks,” because the system understands the connection.
By hosting embedding inference locally, SITE Cloud ensures sensitive data never leaves sovereign infrastructure, enabling organizations to build advanced search and retrieval systems without compliance risks.
Reranking Inference
Reranking inference refines search results or recommendations by applying deeper context.
For example, imagine you search for “apple” in a document library. The first pass might return results about fruit and technology mixed together. Reranking steps in to reorder the results, putting the technology-related ones on top if the system detects you were asking about Apple laptops, for instance.
This extra layer makes outputs more accurate and relevant. SITE Cloud provides secure reranking inference, enabling organizations to fine-tune experiences without exposing sensitive data to foreign providers.
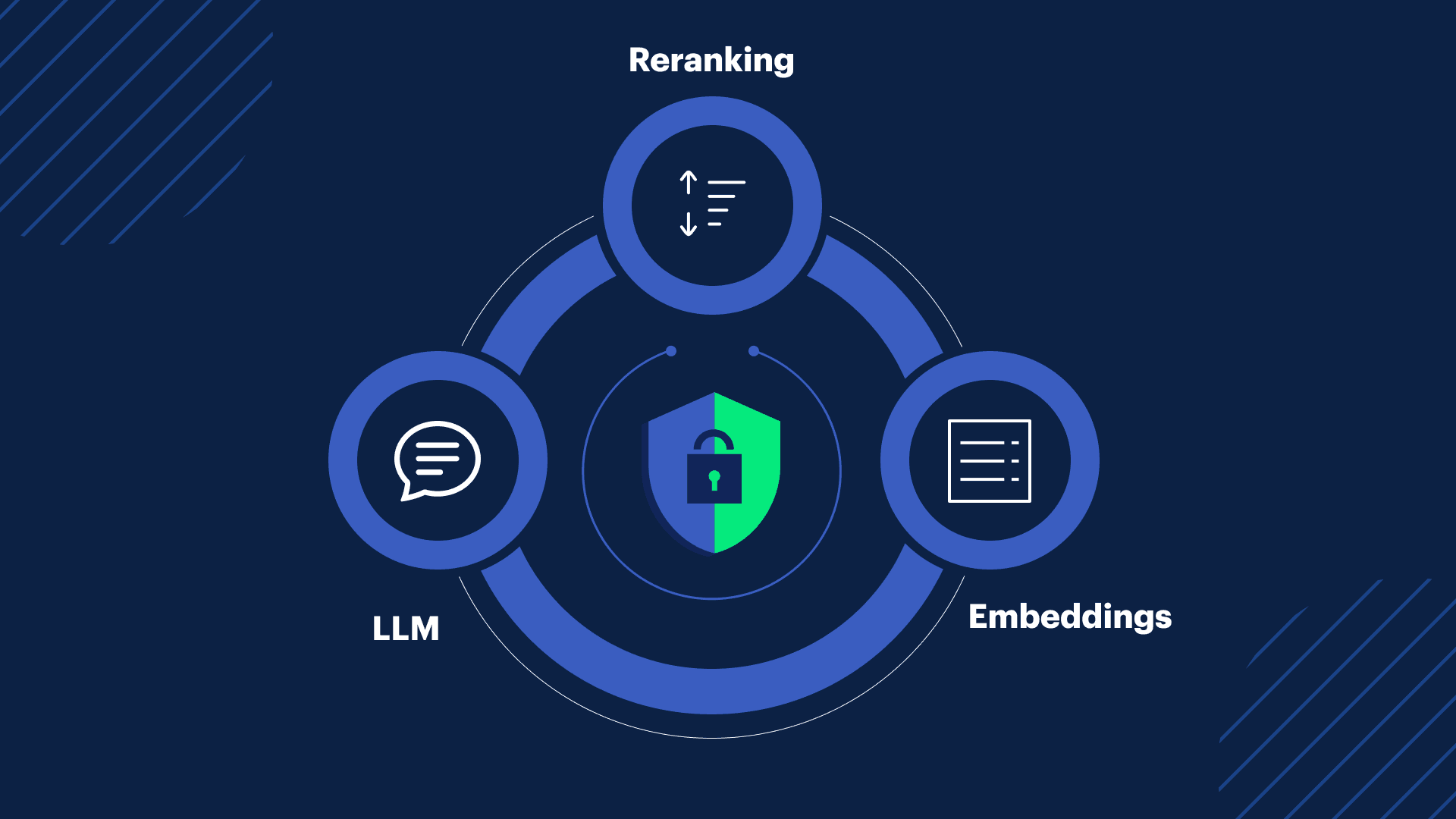
Connecting the Inference Dots
Inference rarely happens in isolation. Different methods often work together to deliver the best results.
A common flow might look like this:
- Embedding inference transforms information into vectors, allowing the system to understand the meaning of queries.
- Reranking inference reorganizes the results from searching embeddings, surfacing the ones that match the user’s intent most closely.
- LLM inference generates a natural, human-like response using the reranked context.
Training and serving models still requires robust GPUs, and the choice of model, whether general purpose, coding, or specialized, determines the quality of the results.
By combining embeddings, reranking, LLM inference, and sovereign GPUs, SITE Cloud provides a complete, secure, and compliant foundation for AI applications.
Conclusion
Inference is the bridge between trained AI models and real-world value. Whether generating text, enabling semantic search, or refining results, inference turns potential into performance.
With SITE Cloud, organizations gain access to all major types of inference within a sovereign, secure environment. This ensures compliance, protects sensitive data, and enables AI innovation without compromise.